Leslie Lei
-
Posts
5 -
Joined
-
Last visited
-
Days Won
3
Leslie Lei's Achievements
")




-
Windows Physical Backup includes Swap File and Too much Data
Leslie Lei replied to John Mallard's topic in Physical Backup
I think Nakivo should change the way the software gathers the data from the server. If the software allows you to exclude the files from the file system, that means the software is looking at the data changes in each file. This is the slowest method when doing data backup because the backup process needs to walk through every file in the file system to determine the changes. I think that is the main reason the physical server backup process takes a very long time even if only a few files get changed. It spends the most of the time walking the file with no changes. The best way to backup the data on the disk is the block-level backup. The software should just take a snapshot of the data blocks on the disk level instead of the individual file level. Slide the disk with multiple (million or billion blocks). Look for the change in each block and only backup the changed blocks. This method will not care what files has changed. Every time a file gets changed, it will change data in the blocks in which the file resides. The backup software just backs up the changed block. This should be the best way for Nakivo to speed up the backup process. I normally put the page file and the printer spooler folder or any file that I don't want to backup in another volume or disk in the Windows system. Skip that disk/volume in the backup job to reduce the change that needs to be backed up. -
The current software doesn't have the option for us to control the number of Synthetic full backups. The best option I can find is to create a Synthetic full every month. Most of our clients are required to store backup data for at least one year. Some clients even require to save backup for 3-10 years. With the current software option, one-year retention will create 12 Synthetic full backups. Even Synthetic full backup doesn't really perform a backup from the protected server to save backup time, it still constructs a full backup from the previous incremental and eat up the storage space. If one full backup takes 1TB, one-year retention means we will need at least 12TB to store the backup. Can Nakivo make a new feature to set the maximum number of Synthetic full backups so we can control how many full backups are in the entire backup storage? We have clients with large file servers that a full backup is more than 3TB.
-
backup slow in EC2 and Physical machine
Leslie Lei replied to Leslie Lei's topic in General backup topics
The ticket is #225141. -
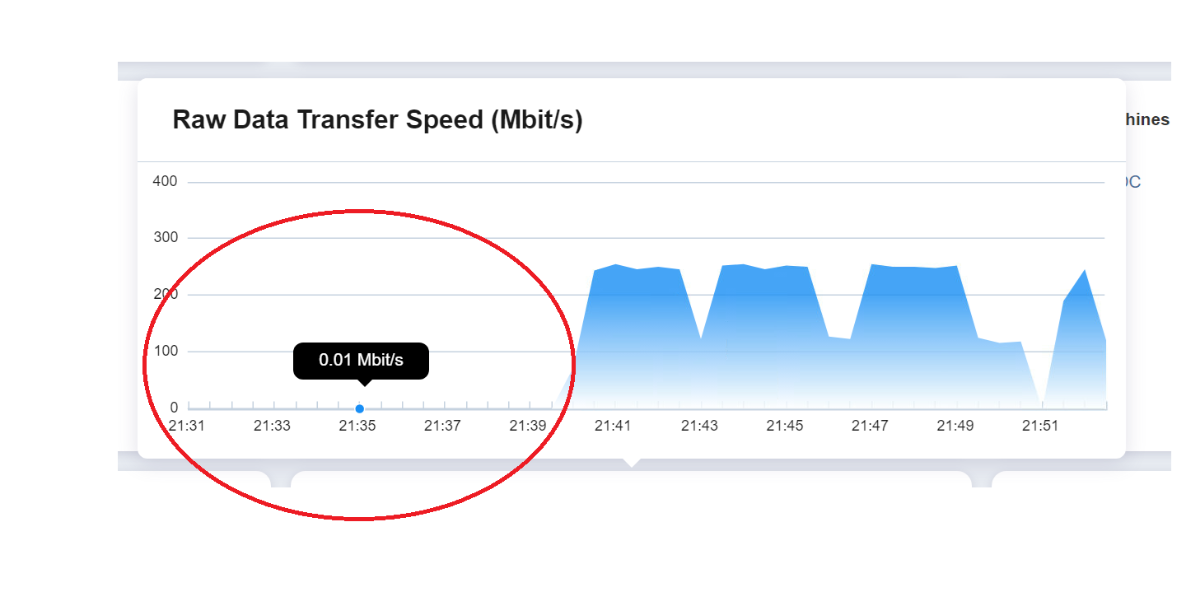
We just tested AWS EC2 and found the job runs slow. The support wasn't able to provide the answer. When backing up EC2 instant, the Nakivo director creates a target machine snapshot and Hotadd the snapshot to the transporter. The transporter reads the data in the snapshot. Because the transporter is a Linux machine and the target server is a Windows server, we can't tell if this is the trouble with the Linux machine reading the Widows NTFS volume. We changed the setup to the Physical machine backup method instead. Basically, we just treat the EC2 server as a physical server and deploy the Nakivo agent on it. Let the agent on the target server collect data from the volume and send it to the Transporter. That eliminates the possible NTFS volume and Linux system issues. The target server and the transporter are also in the same network subnet in AWS to eliminate possible network issues. However, the backup process is still slow. The slowness is not caused by the performance of the target machine, transporter or network. If I watch the backup process (incremental backup), I can see the job starts with 100Mb/s - 300Mb/s at the beginning 10 minutes of the job. After that, the speed will drop to 0.01Mb/s or even 0.0.Kb/s for almost an hour. It will resume the speed to 100-300Mb/s in the last 10 minutes. This backup process makes the backup duration much longer than it should. This issue happens in both AWS EC2 backup and the physical server backup. the VMware backup works fine. For the same-size of server, it only takes about 3 minutes to complete the incremental job for the ESXi VM. I think there is a software bug in the Nakivo software that the change block tracking doesn't work or doesn't work efficiently in the EC2 instant or physical backup job. The job should quickly skip any data blocks with no changes. In the current backup process, I can tell the job is still walking the data block with no changes. It doesn't know which block has no changes or it doesn't know how to skip them. That's why it wastes most of the time to walk through the data with no changes.

-
Leslie Lei joined the community
-
I think the developer made a fundamental mistake here. The repository should be only responsible for storage type (Disk or tape), where the data is stored (local, NAS or cloud), and how the data is stored (Compression and Encryption). The backup job should determine how the data is structured. "Forever incremental" and "Incremental with full" options should be within the job schedule section, and the retention policy determines how long the data should be kept. To determine if the data "Forever incremental" or "Incremental with full" should be the function of the backup job itself, not the function of the repository.