

-
Posts
112 -
Joined
-
Last visited
-
Days Won
5
Posts posted by The Official Moderator
-
-
15 hours ago, raymond.tuleweit said:
It looks like it is not possible to store the M365 backups to a cloud repository as S3 or Wasabi.
Or did I miss something?
The thought storing the M365 data on-premise is different as some competitors and a nice option.
But the time has come where hybrid worlds and cloud-to-cloud "backups" make sense.
Is a cloud repository for M365 in the pipeline?
I don't think the workaround storing M365 data to a local windows repo and making an additional "backup" of that repo to the cloud is a good idea...

@raymond.tuleweit Thank you for bringing up the topic. We're working on adding cloud support for Microsoft 365 backups, allowing storage in cloud repositories like S3 or Wasabi. This feature is planned for release in the near future. Stay tuned for updates and thank you for your feedback!
-
5 hours ago, raymond.tuleweit said:
In the newest version, there are no retention tabs (for setting up the option grand-father-son) anymore? How can it be switched to legacy rentention method?

Hello Raymond, we've reached out to you by email with how to revert to the legacy retention method by logging in to Expert Mode of NAKIVO Backup & Replication.
Our technical team is ready to assist via a remote session if needed. For those interested in how to do this for their instances of NAKIVO Backup & Replication, please refer to: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Expert-Mode.htm?Highlight=expert mode Log in to Expert Mode and change the setting system.job.default.retention.approach to legacy.
Let me know if you have more questions.
-
3 hours ago, octek0815 said:
Hello,
are there any plans for supporting Proxmox in the future?
Regards,
Oliver
Hello Oliver, Proxmox support in NAKIVO Backup & Replication is planned, but we don't have a release timeline yet. I appreciate your patience and will keep the community updated on any progress. Thank you for bringing this up.
-
3 hours ago, octek0815 said:
Hi,
where can i download nakivo 10.11.0 for synology dsm 7 and higher?
Regards,
Oliver
@octek0815, you can find the specific instructions and download link for updating to NAKIVO 10.11.0 on Synology DSM 7 in the following knowledge base article: https://helpcenter.nakivo.com/Knowledge-Base/Content/Installation-and-Deployment-Issues/Updating-Manually-on-Synology-NAS.htm
If you encounter any issues or have further questions while following the steps, feel free to reach out for more assistance.
-
Exciting news! The latest 10.11 version of NAKIVO Backup & Replication is out! The new release comes with new features and enhancements for proactive VM monitoring, faster granular recovery and enhanced workflow management.
- Alerts and Reporting for IT Monitoring Set up custom alerts to detect suspicious activity and get comprehensive reports about VMware VMs, hosts and datastores.
- Backup for Oracle RMAN on Linux Back up Linux-based Oracle databases and instantly restore necessary databases directly from existing backups.
- File System Indexing Create an index for the files and folders in your VMware and Hyper-V backups to streamline file recovery processes.
- Backup from HPE Alletra and HPE Primera Storage Snapshots Back up VMware VMs on HPE Alletra and HPE Primera Storage devices directly from storage snapshots to reduce the impact on production environments.
- In-Place Archive Mailbox, Litigation Hold and In-Place Hold Support Back up Microsoft 365 In-Place Archive mailboxes, Litigation Hold, and In-Place Hold items to comply with legal requirements. Recover folders, files, and other items to the original or a different user account.
- Universal Transporter Use a single transporter to discover and manage diverse workloads residing on the same host.
The new features in NAKIVO Backup & Replication v10.11 are available to try for free! Download the full-featured Free Trial and try the latest functionality in your environment today.
-
Navigating the dynamic data protection landscape can be a challenging and unpredictable task. Surprises await at every corner, from groundbreaking innovations to more sophisticated threats.
Do you have what it takes to protect your organization and its data from the risks to come in 2024? Take our maze-themed quiz to test your knowledge of key data protection trends and find out. Challenge your colleagues and friends to take the quiz and see how you stack up against them: https://www.proprofs.com/quiz-school/ugc/story.php?title=nextgen-data-protection-what-to-expect-in-2024t1
-
On 1/22/2024 at 4:09 PM, Viktor Soldan said:
I would like to ask a few questions regarding the site recovery VMware VM script
- where could be stored ths script on a director or inside the VM ?-what username/password should be used VMware or the guest ?
-Is it necessary to have any open ports between director and the VM or communication between the director and host is sufficient ?
Thank youHello @Viktor Soldan, To run the script on the specified host, NAKIVO Backup & Replication logs in to the host, that is, via SSH, using the credentials specified in the run script action settings. The script should be located on a VM in the specified location.
It's important that no third-party software, such as firewalls or antivirus programs, interfere with the login attempt. If you encounter any issues or have further questions, feel free to ask.
-
Special Offer for Attendees
Attend the webinar for a chance to win*:
$50 Amazon eGift Card in a lucky draw during the webinar
$25 Amazon eGift Card in a random drawing for completing a post-webinar survey
Technology is evolving at a rapid pace, making it critical for organizations to adopt dynamic and proactive data protection strategies. In 2024, generative AI and digital transformation are only two of many trends that will affect the operational resilience of SMBs and enterprises alike.
Register for our upcoming webinar to learn about the most important data protection and cybersecurity trends to watch out for in the year ahead, and get exclusive predictions and strategic guidance directly from NAKIVO experts, Q&A included.
Get free access to the recorded webinar "Real-Time Replication: How to Build a More Resilient IT Infrastructure" as a bonus for registering.
Attendance is limited – save your spot for free now!
What it covers
-
Data Protection Trends in 2024
-
AI and ML: Innovations and downsides
-
Beyond 3-2-1: Backup strategies revisited
-
BaaS and the next big thing for MSPs
-
Hybrid and multi-cloud are the new normal
-
Rising demand for real-time analytics
-
Cybersecurity and the ransomware boom
-
The curious case of cloud repatriation
-
-
NAKIVO’s 2024 Predictions
-
AI and compliance: An asset, or a liability?
-
Zero-Trust security is the way to go
-
Explosion of AI-driven cyber attacks
-
New steps to combat generative AI abuse
-
More investment in cybersecurity training
-
Real-time data protection becomes a priority
-
-
Q&A session
When to attend
-
EMEA: January 31, 2024, 5 PM - 6 PM CET
-
Americas: January 31, 2024, 11 AM - 12 PM EST
BONUS: Get a free copy of NAKIVO’s Top Data Protection Trends in 2024 white paper for attending.
*Terms and conditions apply.
-
-
16 hours ago, ExploreTheWorldWithMe said:
Hello,
Does anyone have the URL for the DSM 7 Synology arm v8 script updater for v10.11 BETA?
Here's a sample link: https://d96i82q710b04.cloudfront.net/res/product/DSM7/NAKIVO_Backup_Replication_v10.10.1.78665_Updater_Synology_arm_v8.sh
I found the URL here: https://helpcenter.nakivo.com/Knowledge-Base/Content/Installation-and-Deployment-Issues/Updating-Manually-on-Synology-NAS.htm
However, I couldn't find the same URL for v10.11 BETA in the beta documentation.
Thanks!
Have a nice day.
Hello @ExploreTheWorldWithMe Since DSM 7.0, Synology has to sign for all applications installed on their devices.
So, our test/beta version is only available for a short time before the GA version, and it cannot be installed on DSM 7 without the signed package from Synology. You can try our 10.11 beta version by using another platform, for example, Windows, Linux, NAS from another vendor... https://www.nakivo.com/resources/releases/beta/
Let us know if you need further assistance.
-
8 hours ago, sathya said:
Hi,
I have searched the API documentation to clone Job and could not found it. Can anyone share the code to clone a Job using API
@sathya Until the API documentation becomes available, you can manually clone jobs from the NAKIVO Web UI. Please check the following user guide for the detailed steps: https://helpcenter.nakivo.com/User-Guide/Content/Getting-Started/Managing-Jobs-and-Activities/M365-Managing-Jobs.htm?Highlight=clone#Cloning.
-
5 hours ago, sathya said:
Hi,
I have searched the API documentation to clone Job and could not found it. Can anyone share the code to clone a Job using API
@sathya, thank you for your post. I will forward this information to our DOC and DEV Teams to create a documentation on our website based on your request. I will let you know when it is ready to use.
-
7 hours ago, Matt Belben said:
We have an issue where our transporters are not passing data at the expected 1GB rate.
I have reached out to Nakivo with no response yet but wasn't sure if there was some sort of software hard limit?I have a copy job that runs at 1GB speed but anything using vmware transporter is bottoming out at around 450mb.
Hello @Matt Belben
NAKIVO Backup & Replication uses all resources available to it to execute a job. If a job is running too slowly, there may be a resource shortage for some of the operations part of a backup job: reading data from source, writing data to target or transfers over the network.
To help us identify the bottleneck that's slowing down the job, please enable the "Bottleneck detection" option in the job settings for at least one VM and complete at least one full backup run.
For step-by-step instructions, you can check the following link:
https://helpcenter.nakivo.com/User-Guide/Content/Backup/Creating-VMware-Backup-Jobs/Backup-Job-Wizard-for-VMware-Options.htm#DataPlease send us a support bundle afterward (https://helpcenter.nakivo.com/display/NH/Support+Bundles) to support@nakivo.com and specify the job name, and if specific VMs are affected, provide their names and we will investigate the issue.
Looking forward to hearing from you.
-
5 hours ago, Matt Belben said:
We have an issue where our transporters are not passing data at the expected 1GB rate.
I have reached out to Nakivo with no response yet but wasn't sure if there was some sort of software hard limit?I have a copy job that runs at 1GB speed but anything using vmware transporter is bottoming out at around 450mb.
@Matt Belben Hello, your request has been forwarded to our Level 2 Support Team. Were you able to send a support bundle to support@nakivo.com when requesting assistance?
If not, the best thing would be to generate and send a support bundle (https://helpcenter.nakivo.com/display/NH/Support+Bundles) to our support team as this would speed up the investigation and resolution of the issue.
Thank you.
-
On 12/14/2023 at 11:02 AM, asecomputers said:
Hi,
Im currently backing up Exchange Online through Nakivo, I also want to keep a copy of these backups offsite for redundancy. I cant find an easy (without extra licenses also) way of doing this.
The only method that i can use reliably is creating a another Backup job with a different Transporter at my offsite location and running the backup again, whilst this works well im duplicating my licence costs. Is there a better way of doing this please?
Hello @asecomputers,
NAKIVO Backup & Replication does not support backup copy for Microsoft 365 data for now. But there are workarounds that you can use:
1) Deploy an additional Transporter on your offsite location and add the Transporter to the existing NAKIVO Director instance.
2) Create a SaaS repository on the newly deployed Transporter host.
3) Set up an additional backup job pointing to the newly created repository.
While we understand that this may not be the ideal solution, it can help achieve redundancy without adding license costs.
Don't hesitate to reach out if you have any more questions or need further assistance.
-
7 hours ago, asecomputers said:
Hi,
Im currently backing up Exchange Online through Nakivo, I also want to keep a copy of these backups offsite for redundancy. I cant find an easy (without extra licenses also) way of doing this.
The only method that i can use reliably is creating a another Backup job with a different Transporter at my offsite location and running the backup again, whilst this works well im duplicating my licence costs. Is there a better way of doing this please?
@asecomputers Hello, your information/request has been received and forwarded to our Level 2 Support Team.
Meanwhile, the best approach would be to generate and send a support bundle (https://helpcenter.nakivo.com/display/NH/Support+Bundles) to support@nakivo.com so our Technical Support team can provide swift assistance.
Thank you.
-
On 12/12/2023 at 10:30 AM, Mikalo said:
This is the error:
VM cannot be processed"ASERVER" VM cannot be processed. Time spent: 18 seconds. Reason: RefreshJobObjectResources: rawFaultCode: ServerFaultCode, rawFaultString: Cannot complete login due to an incorrect user name or password. (InvalidLogin).
@Mikalo , there are 3 different sets of credentials in your case:
1. Based on the screenshot, there's the Linux OS password.
This password gives shell access. It is necessary if you need to check NAKIVO Backup & Replication logs or reset the Web GUI password.
2. NAKIVO Backup & Replication GUI password.
This password gives you access to the NAKIVO Backup & Replication web UI, that is access to jobs, configurations and your data protection infrastructure. To chage or recover this password, please refer to the following article: https://helpcenter.nakivo.com/User-Guide/Content/Getting-Started/Logging-in-to-NAKIVO-Backup-and-Replication.htm?Highlight=password#Changing
3. VMware Center or standalone ESXi credentials.
These credentials allow you to add vCenter to the NAKIVO Backup & Replication inventory. For information on how to add vCenters and ESXi hosts to Inventory, please refer to this article: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Inventory/Adding-VMware-vCenters-and-ESXi-Hosts.htm
Let us know if you need further assistance.
-
On 12/5/2023 at 11:34 PM, Leslie Lei said:
The current software doesn't have the option for us to control the number of Synthetic full backups. The best option I can find is to create a Synthetic full every month. Most of our clients are required to store backup data for at least one year. Some clients even require to save backup for 3-10 years. With the current software option, one-year retention will create 12 Synthetic full backups. Even Synthetic full backup doesn't really perform a backup from the protected server to save backup time, it still constructs a full backup from the previous incremental and eat up the storage space. If one full backup takes 1TB, one-year retention means we will need at least 12TB to store the backup. Can Nakivo make a new feature to set the maximum number of Synthetic full backups so we can control how many full backups are in the entire backup storage? We have clients with large file servers that a full backup is more than 3TB.
@Leslie Lei I forwarded your post to our development team, and they have suggested submitting an official feature request.
To assist our team in better understanding your environment and solution plan, please consider sending us a support bundle. For information on how to do this, please refer to: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Support-Bundles.htm
-
6 hours ago, Mikalo said:
Good morning, I have problems with the backup of nakivo22, I started working in the state computer and the previous computer technicians who were had nothing organized and were unreliable people, to change the password of the user of the VMware I jumped that Nakivo can not access the VMware to make backups, you need new credentials, where I can reconfigure the new credentials nakivo so that it can return to access the VMware and can complete the backups ? the nakivo22 is installed inside a linux in ubuntu console mode.
Thanks!
@Mikalo, Hello, your information/request has been received and forwarded to our Level 2 Support Team. Meanwhile, the best approach would be to generate and send a support bundle (https://helpcenter.nakivo.com/display/NH/Support+Bundles) to support@nakivo.com so our Technical Support team can provide the required assistance.
Information about your environment and setup are important for a swift resolution of your issue. Thank you.
-
On 12/5/2023 at 11:26 PM, DWigginsSWE said:
We're using Nakivo 10.8.0. It's provided as a Service by our hosting provider - they maintain the console, we have a dedicated transporter and we collocate a Synology NAS for storage of our backups.
I have a file server backup job that required about 3.75TB for a full backup, and generates incrementals of a couple hundred gig/night. I've got the backup job set to run a full every weekend and then incrementals during the week. I have enough space on the NAS to keep about a month's worth of nightly recovery points. I have retention settings currently defined on the job that will eventually exceed my available space, but I haven't hit the wall yet.
I'd like to start using a backup copy job to S3 to stash extra copies of backups and also build a deeper archive of recovery points. I'd like to keep about 2 weeks worth of nightly recovery points in S3, then 2 more weeks of weekly recovery points, then 11 more monthly recovery points, and finally a couple yearly.
I built a backup copy job with the retention settings specified, and then ran it. My data copy to S3 ran at a reasonable fraction of the available bandwidth from my provider. However, once the first backup was copied up to S3 in 700+ 5GB chunks, it took an additional 60+ HOURS to "move" the chunks from the transit folder to the folder that contained that first backup. All told, it was 100 hours of "work" for the transporter, and only the first 35ish were spent actually moving data over the internet from our datacenter to S3.
Either I've failed spectacularly at setting up the right job settings (a possibility I'm fully prepared to accept - I just want to know the RIGHT way), or the Nakivo software uses a non-optimal set of API calls when copying to S3, or S3 is just slow. I've read enough case studies and whatnot to believe that S3 can move hundreds of TB/hour if you ask it correctly, so 60 hours to move <5 TB of data seems like something is wrong.
So, my questions are these - what's the best way to set my retention settings on both my backup job and my backup copy jobs so that I have what I want to keep, and how do I optimize the settings on the backup copy to minimize the amount of time moving data around? The bandwidth from my datacenter to S3 is what it is and I know that a full backup is going to take a while to push up to Uncle Jeff, but once the pieces are in S3 what can be done to make the "internal to AWS" stuff go faster?
Hello, @DWigginsSWE, thank you for your patience during our investigation. In response to your query, I'd like to clarify that, indeed, in the current NAKIVO workflow for S3 repositories, data is initially copied to a "transit" folder and subsequently merged into the repository.
However, it's essential to note that the duration of moving data from the "transit" folder depends on the volume of the data being transferred. In some cases, this step may take more time.
For now, it's not possible to improve the performance of this last step as it is done on the S3 repository side after the solution's API request. Should you require any further assistance or have additional questions, please don't hesitate to reach out by email: support@nakivo.com.
-
17 hours ago, Leslie Lei said:
I think Nakivo should change the way the software gathers the data from the server. If the software allows you to exclude the files from the file system, that means the software is looking at the data changes in each file. This is the slowest method when doing data backup because the backup process needs to walk through every file in the file system to determine the changes. I think that is the main reason the physical server backup process takes a very long time even if only a few files get changed. It spends the most of the time walking the file with no changes.
The best way to backup the data on the disk is the block-level backup. The software should just take a snapshot of the data blocks on the disk level instead of the individual file level. Slide the disk with multiple (million or billion blocks). Look for the change in each block and only backup the changed blocks. This method will not care what files has changed. Every time a file gets changed, it will change data in the blocks in which the file resides. The backup software just backs up the changed block. This should be the best way for Nakivo to speed up the backup process.
I normally put the page file and the printer spooler folder or any file that I don't want to backup in another volume or disk in the Windows system. Skip that disk/volume in the backup job to reduce the change that needs to be backed up.
Hello, @Leslie Lei,
Thank you for your post. We acknowledge the importance of optimizing the backup process for efficiency. Currently, we leverage VSS/LVM-based snapshots to read data from the source physical host whenever possible. Our approach involves comparing data with existing backups using hash sums to determine changes at the block level. We do not use file-level comparisons.
In instances where snapshotting is not possible, we resort to low-level reading by sectors on the source disk.
The existing change tracking mechanism is not ideal, and we are working on improvements to speed incremental backups. This improvement has been added to our development roadmap, although a specific ETA is not available at this stage.
We have also forwarded your request to our development team. To help our team understand your environment and solution plan, consider sending us a support bundle. For information on how to create and send a support bundle, please refer to: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Support-Bundles.htm
We value your input and look forward to any further insights you may have.
-
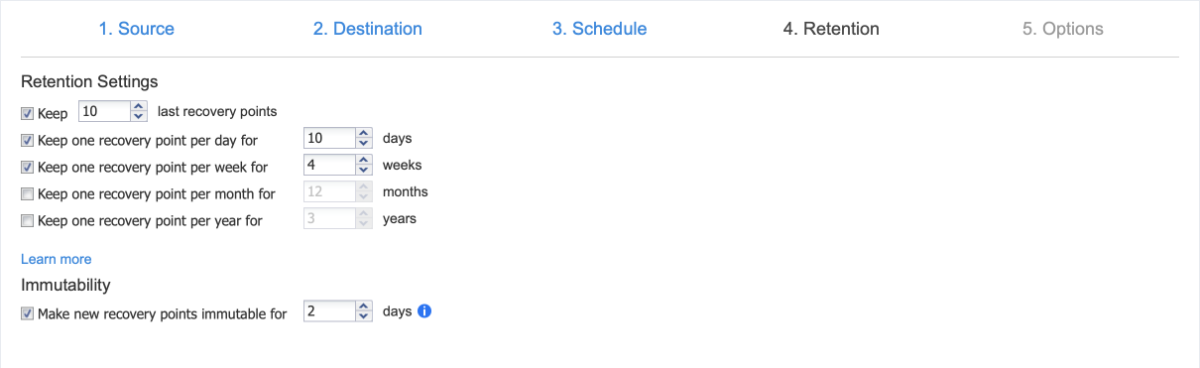
17 hours ago, Leslie Lei said:
The current software doesn't have the option for us to control the number of Synthetic full backups. The best option I can find is to create a Synthetic full every month. Most of our clients are required to store backup data for at least one year. Some clients even require to save backup for 3-10 years. With the current software option, one-year retention will create 12 Synthetic full backups. Even Synthetic full backup doesn't really perform a backup from the protected server to save backup time, it still constructs a full backup from the previous incremental and eat up the storage space. If one full backup takes 1TB, one-year retention means we will need at least 12TB to store the backup. Can Nakivo make a new feature to set the maximum number of Synthetic full backups so we can control how many full backups are in the entire backup storage? We have clients with large file servers that a full backup is more than 3TB.
Hello, @Leslie Lei. We are currently working on improvements to the retention policies in our software to be included in a release in early 2024.
In the meantime, as a temporary solution, you can enable the legacy retention approach. To enable this approach, in expert settings, you should activate the "Legacy" parameter "system.job.default.retention.approach" accessible in the expert settings. For more details: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Expert-Mode.htm).
With the legacy retention approach, you can specify the backup storage duration for 3 years, for example. Important: If setting for 3 years, the parameter should be set to 4 to achieve the goal you described - 3 for the past 3 years plus 1 for this year.
-
5 hours ago, dmgeurts said:
Is there any way of having this detail added to the messages in the Director? I'd hate to leave debugging turned on permanently to have visibility of this.
Hello, @dmgeurts
We'll forward your request to our development team.
To help our team understand your environment and solution plan, consider sending us a support bundle.
For information on how to create and send a support bundle, please refer to: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Support-Bundles.htm
-
17 hours ago, DWigginsSWE said:
We're using Nakivo 10.8.0. It's provided as a Service by our hosting provider - they maintain the console, we have a dedicated transporter and we collocate a Synology NAS for storage of our backups.
I have a file server backup job that required about 3.75TB for a full backup, and generates incrementals of a couple hundred gig/night. I've got the backup job set to run a full every weekend and then incrementals during the week. I have enough space on the NAS to keep about a month's worth of nightly recovery points. I have retention settings currently defined on the job that will eventually exceed my available space, but I haven't hit the wall yet.
I'd like to start using a backup copy job to S3 to stash extra copies of backups and also build a deeper archive of recovery points. I'd like to keep about 2 weeks worth of nightly recovery points in S3, then 2 more weeks of weekly recovery points, then 11 more monthly recovery points, and finally a couple yearly.
I built a backup copy job with the retention settings specified, and then ran it. My data copy to S3 ran at a reasonable fraction of the available bandwidth from my provider. However, once the first backup was copied up to S3 in 700+ 5GB chunks, it took an additional 60+ HOURS to "move" the chunks from the transit folder to the folder that contained that first backup. All told, it was 100 hours of "work" for the transporter, and only the first 35ish were spent actually moving data over the internet from our datacenter to S3.
Either I've failed spectacularly at setting up the right job settings (a possibility I'm fully prepared to accept - I just want to know the RIGHT way), or the Nakivo software uses a non-optimal set of API calls when copying to S3, or S3 is just slow. I've read enough case studies and whatnot to believe that S3 can move hundreds of TB/hour if you ask it correctly, so 60 hours to move <5 TB of data seems like something is wrong.
So, my questions are these - what's the best way to set my retention settings on both my backup job and my backup copy jobs so that I have what I want to keep, and how do I optimize the settings on the backup copy to minimize the amount of time moving data around? The bandwidth from my datacenter to S3 is what it is and I know that a full backup is going to take a while to push up to Uncle Jeff, but once the pieces are in S3 what can be done to make the "internal to AWS" stuff go faster?
@DWigginsSWE, hello, your information/request has been received and forwarded to our Level 2 Support Team.
Meanwhile, the best approach would be to generate and send a support bundle (https://helpcenter.nakivo.com/display/NH/Support+Bundles) to support@nakivo.com so our Technical Support team can investigate your issue having more details.
Thank you.
-
23 hours ago, dmgeurts said:
So it turns out that if Malware is found in a user's OneDrive you get an alert. The issue is that there's no information included about which file or folder is affected or what type of malware was detected.
Has anyone dealt with this? Does Nakivo exclude the affected files from the backup? How can one flag things if it's a false positive?
I'm not a Windows person so any pointers on how to deal with malware on a user's OneDrive would be most welcome too.
@dmgeurts for a more thorough investigation, please follow these steps:
1) Enable Expert Mode: Navigate to Expert Mode: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Expert-Mode.htm and activate 'system.debug.mode.enabled.'
2) Activate Debug Mode on Transporter: Access the transporter linked to the M365 repository and turn on debug mode. You can find details here: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Nodes/Managing-Nodes/Editing-Nodes.htm
3) After completing these steps, rerun the job and generate a new support bundle, ensuring it includes the main database.
Please describe the issue when sending the support bundle and mention your ticket number #230026.
For details on creating a support bundle, refer to this page: https://helpcenter.nakivo.com/User-Guide/Content/Settings/Support-Bundles.htm
Looking forward to hearing from you.


FBLD.jpg.52b70cbb14c1361aad1a9b937966fa9d.jpg)
Support for XCP-NG and XOA
in General threads
Posted
Dear @Alex.cartus, thank you for your query. Currently, NAKIVO does not support XCP-NG in combination with XOA. We've noted your interest and have created a feature request for future versions. Keep an eye on our updates for any news on this. For any questions, feel free to reach out to our support team.